Linux Migration de CentOS 7 vers CentOS StreamCentOS 7/8 sont officiellement obsolètes. Ainsi Il faut absolument passer à une alternative CentOS ( Ex : Migration vers Rocky…
Linux Définir temporairement une adresse IP sur un OS LinuxLa configuration temporaire d’une adresse IP statique sur un système Linux est utile dans les situations où vous devez résoudre…
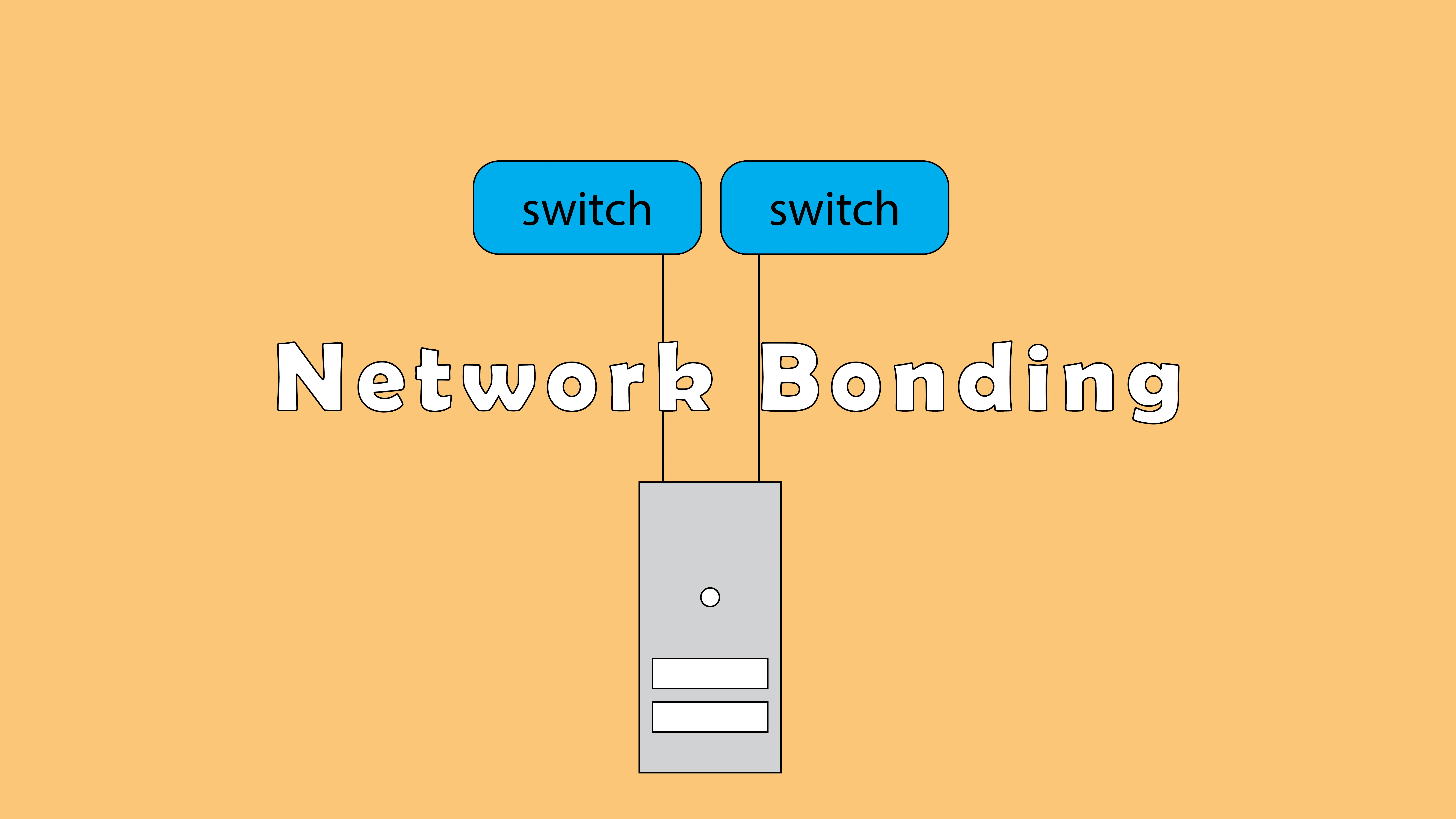
Linux Configurer le bonding réseau avec nmcli sous LinuxLe Bonding réseau permet de grouper deux interfaces réseau physiques ou plus pour créer une interface logique. Permettant ainsi de…
Linux 7zip: 9 Commandes utiles de les plus utilisés7zip est un logiciel de compression open source multiplateforme. C’est un outil très efficace supportant plusieurs format comme 7z, ZIP,…
Linux tar: Les 14 commandes les plus utilisétar ( tape archive ) est la commande Linux la plus utilisée pour créer des fichiers d’archives compressés qui peuvent…
Linux Migrer Rocky Linux 8 vers Rocky Linux 9Dans l’article précèdent, nous avons vu comment migrer l’OS CentOS 7 vers Rocky Linux 8. Maintenant nous continuer la migration…
Linux Migrer CentOS 7 vers Rocky Linux 9CentOS 7 n’est plus supporté, ce qui signifie qu’il ne reçoit plus de mis à jours de sécurité ou de…
Linux Empêcher les utilisateurs sudoers d’exécuter des cmds sudoSudoers ou super-utilisateurs sont des utilisateurs avec des privilège root. Un utilisateur sudoers a la possibilité d’exécuter une ou plusieurs…
Linux nmtui : Configurer une adresse IP sous LinuxSi vous avez l’habitude de d’utiliser l’OS Redhat/centos/rocky linux , vous avez surement utiliser la commande nmcli pour configurer l’adressage….
Linux Comment installer Nginx on Rocky Linux 9Nginx est l’un des serveurs web les plus populaires au monde. Il permet d’héberger les sites web et est responsable…